
Operations engineering has a strong tradition of learning from other industries. Many lessons have come from failures in medical devices, space missions, and of course the recent Boeing 737MAX software-related tragedies.
James Hamilton’s excellent studies of the Costa Concordia grounding, the Fukushima meltdown, the USS Fitzgerald collision, the Volkswagen emissions scandal stand out — so do John Allspaw’s writings on Resilience Engineering, systems thinking and safety, and engineering complex systems. I should also mention Google's SRE Book.

I live to ride the mountains — but skiing comes with some inherent dangers. Here in Colorado, we can see it, with 137 fatalities in the past decade.
From collisions to lift accidents — loading injuries to avalanches, the commercial ski industry deals with life-and-death situations every day.
With 85 years more experience than we have in SRE/DevOps… what DevOps-related lessons can we take from the ski industry?
Engage Your Users
It makes for a good drama to talk about lift failures, but they make up a tiny portion of the risk a skier faces on the mountain. Collisions and natural conditions are far more likely to get you — and managing these risks is mostly up to the skier or snowboarder.
The ski industry takes a proactive approach to user education — something that should encourage us to share more with our development teams and end-users:
- Ski patrol spends every morning marking and re-marking trail boundaries, difficulties, trees, stumps, cliffs and more. In extreme terrain, you’ll run into “Unmarked Obstacles Exist” signs and know you’re in risky territory. Solid documentation is essential for successful IT operations and breaking down DevOps silos. I recently consulted with a Colorado startup that uses ski trail icons to mark the risk of their production run books — good stuff!
- Ski with a buddy: Tree wells are deadly, and the mountains are full of “unknown unknowns.” Just last year while skiing the trees at Copper, I fell head-first into an old mine shaft entrance! Where does cross-training and pairing rank on your team’s priority list?
- Every year, skiers die for completely avoidable reasons: skiing out of control into a tree or person, crashing without a helmet, ducking ropes, or being unprepared for rapidly changing mountain weather. You can’t force your users to act wisely, but you can certainly help push them in the right direction. The National Ski Areas Association engages in a variety of seasonal and year-round safety awareness programs. When’s the last time your organization has had a meaningful security education campaign for ops, developers, or end-users?

Incidents Happen
One of my strongest memories as a seven-year-old is skiing the newly-opened “North Face” at Keystone. After a few amazing runs, we rode the new Teller Lift back to the front of the mountain. Less than a month later, the bullwheel fell off the top of the lift, killing two and injuring dozens.
Keystone Ski Patrol’s incident response was admirable:
- Communications: Equipped with two-way radios, the Lift Operations team was able to notify Ski Patrol within moments of the incident. Does your incident escalation system (Slack/PagerDuty/email/etc.) allow you to get the right stakeholders involved, immediately? Do you truly communicate honestly with end-users during an incident?
- Life Safety Skills: Ski Patrol are all trained EMTs, and most have decades of emergency medical, avalanche, and mountaineering experience. If a guest gets hurt at a ski resort, they are in the hands of a first-class first-responder armed with the tools to save a life. Does your on-call team have the training and access to production they truly need to mitigate real-time issues?
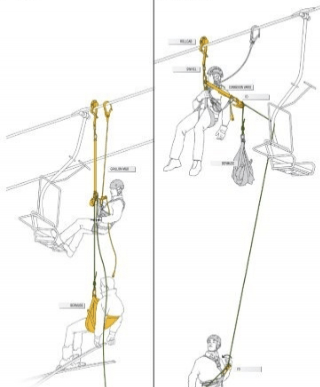
- Lift Evacuation: If a tree falls in the woods, on a lift cable, can you hear it? Oh yes!! No matter why the lift is disabled, Ski Patrol has several methods to get guests to the ground safely. In the Teller incident, Keystone Ski Patrol was able to unload every stranded guest to safety. Does your team know how to handle rollbacks? What about dealing with data corruption?
Ultimately, the engineering failure was ultimately linked to a manufacturing defect in the top bullwheel’s main drive shaft. This critical component is a single-point-of-failure — when it broke, a shockwave was sent down the cable, flipping riders and chairs to the ground. A positive outcome came when the same defect was found in 11 other lifts across the country — potentially saving many lives.
Today’s lift systems are loaded with sensors that can automatically stop the lift in case of critical component failure or tower derailment. Newer lifts have four independent braking systems and hundreds of safety sensors and controls. What unexpected single points of failure exist in your critical environment? DNS, TLS Certificates, and even “HA” databases are often a surprise.
Like it or not, you’re Testing In Production!
Colorado ski resorts do an excellent job providing a safe trip up the mountain. But there’s no denying that every running lift on the mountain is “in production.” There really is no SLA regarding serious incidents — the PR, legal, and financial incidents of a single incident could shutter a resort.
In the SRE/DevOps world, we know it’s almost impossible to build a test environment that exactly matches production. Cost, logistics, and engineering effort make a truly identical test environment a rare luxury. Similarly, in the ski industry, it’s just not reasonable to imagine “test” lifts operated under real conditions.
If you aren't testing in prod you aren't testing in 💥reality💥 -- just a weak dime store knockoff. Then you light the fuse and walk away with your fingers crossed.
— Charity Majors (@mipsytipsy) July 7, 2019
Test in prod. Please. https://t.co/5ftrmBhoOL
In Ops, we often take comfort in A/B tests, canary tests, staged rollouts, feature flags, and so on. Chaos engineering builds confidence in our HA controls. We feel (rightly so) that risk to production is lowered. These are indeed powerful tactics, but sometimes make us overconfident.
Even in a controlled test, it’s important to remember that risk to production is non-zero. New code might still cause tricky performance or memory bugs, even if disabled by a feature flag. A staged rollout with incorrect schema changes could corrupt your production database. Chaos engineering can occasionally cause unexpected outcomes.
In the ski industry, the planned Eskimo Lift destruction at Winter Park is well-known, both for the valuable lessons learned, and the unexpectedly-violent way the lift self-destructed:
Do you have the observability necessary to know when things start to go wrong in production before it impacts your users? Is time spent on non-production environments impacting what gets done in production? Does your team understand the risk that various production experiments pose?
Choose Boring Tech
One of the greatest improvements Copper Mountain has made recently was the new American Flyer lift. I’ve heard that it’s the first electronic direct-drive, gear-less alpine lift. Basically, a huge, quad-copter motor. It’s a great step for the industry and consumes significantly less power than traditional lifts.
Copper got the Flyer running last year with just a couple of road bumps. But even with the technology working, users of the lift ran into (UI/UX) issues. The non-traditional lift line caused confusion — occasionally people fell or missed their chair. A detachable six-person lift, it’s the heaviest and longest bubble lift ever — guests experienced thrilling “bounces” when the lift stopped.
This year, the lift line was re-arranged to grant users a full 180-degree view of the incoming chair… the loading problems have disappeared! New lift towers were added and slack removed from the cable… the ride is smooth as butter.

It was perhaps just too much innovation at once.
If you haven’t seen Dan McKinley’s Choose Boring Technology site — please check it out.
Let’s say every company gets about three innovation tokens. You can spend these however you want, but the supply is fixed for a long while. — Dan McKinley
How is your organization using your innovation tokens? Does that bleeding-edge technology really differentiate your business?
Embrace 3rd-Party Review
As a security engineer, I always encouraged a third-party security audit before launching big new features. Besides being a requirement of most IT security standards, it just makes common sense. A 3rd-party audit is essential when it comes to security or life-safety

Colorado is one of only nine states that have any regulatory board managing ski area safety (as of 2016). Of those, only Colorado and Vermont actually perform in-person inspections.
California’s State Congress passed ski safety regulations twice, only to be vetoed by Governors Schwarzenegger (R) and more recently Brown (D). Today, California ski resorts have no obligation to report serious incidents, and guests have no way to know how safe their experience will be.
The Colorado Passenger Tramway Safety Board offers balanced regulation over safety-critical services, employing full-time staff to make both scheduled and unannounced inspections. New or updated lifts are load-tested, and the ANSI B77.1–2017 safety standard is enforced (the standard is optional in most places).
Does your organization regularly engage 3rd-party auditors, reviewing both software and operations? Does everyone on your team have a good understanding of your organization’s compliance requirements? Do you have a bug bounty program?
Incident Postmortem
The Colorado Passenger Tramway Safety Board’s incident reporting and follow-up process is well-defined and — impressively— exemplifies many of the qualities of a best-practices blameless post-mortem:
A Formal Incident Reporting Process is Defined

Specific SLOs and Details are Captured

A “Blameless” Approach
The Tramway Safety Board takes a “blameless” approach: public incident data includes anonymized lift and resort information. This anonymity trades public transparency and awareness to help ensure more complete reporting by the commercial ski resorts. Still, it’s not like ski resorts are unaccountable — the courts still preside over criminal and civil offenses.
Sharing Failures Benefits All
Remember the Teller lift incident at Keystone? Well, it was re-opened the following year as the Ruby lift. And the lessons learned resulted in changes not just at Keystone, but across the industry.
Similar industry improvements came from the Sierra incident at Copper:
Kramer illustrated the point with a 2006 Sierra Chair structural malfunction that caused two individuals to fall to the ground at Copper. They weren’t injured, but the incident was reported as usual and led to changes at other resorts that also used the Yan fixed-grip triple chair.
The Tramway Safety Board monitors its incident database to look for trends. As Copper replaced its chairs, “other areas found similar defects in the carriers before anything happened,” Kramer said. — via summitdaily.com
Have Fun!
Whatever your goal, try to have some fun along the way.
As a daily skier/snowboarder at Copper Mountain, I feel good watching the Ski Patrol head up the lifts at about 8:12 every weekday. Along with the Lift Ops and Mountain Ops teams, their dedication to the user’s safety, experience, and enjoyment is an inspiration for all of us in the SRE/DevOps world!
In fact, maybe I will write about DevOps Lessons from the Hospitality Industry in the future!!

Looking for help with your DevOps/SRE strategy? I'm focused where software, infra, and data meets security, operations, and performance. Follow or DM me on twitter at @nedmcclain.